
LLM与本地知识库
目录如下
一些基本概念
知识库为什么需要大模型
使用Llamaindex连接大模型和本地知识库
需要处理的问题
一些基本概念
- embedding: 嵌入是一种向量表示,用于保留数据(例如一些文本)的内容和/或意义的维度。在某种程度上相似的数据块往往具有更接近的嵌入向量,而不相关的数据则相距较远。
- tokens: 大模型处理数据的最小单位,一般中文1个字代表一个token, 英文的话一般一个token=0.75个英文单词
知识库为什么需要大模型
我们来看一个日常工作中常见的工作流
- A: xxxxx, 这个是什么原因啊
- B: 稍等,我看下哈
- 如果【大脑检索】xxxx问题出现过,根据记忆来回答问题
- 如果【大脑检索】xxxx问题出现过, 但具体结论之类的忘了,但是记录了文档, 那就需要根据关键词从【文档中检索】
- 如果【大脑检索】xxxx问题出现过, 但具体结论之类的忘了,也没有记录文档,那就需要重新根据问题排查问题了
- 如果【大脑检索】xxxx问题未出现过, 处理方案同上
上面这个工作流,从耗时来说 1, 2 << 3,4
也是日常工作的非常常见的工作流, 那么这里的问题就转化两个步骤
- 为你初次处理此问题的上下文,处理流程是否保存完备
- 以及当我们在搜索时, 能够较为方便的搜索到初次处理问题的文档
步骤1 完全靠自己自觉了, 我们可以操作的部分就是步骤2了
步骤2的核心就是搜索了, 有了google/百度搜索工具之后, 人类利用知识的效率大大提升, 可以想象一下,没有搜索引擎之前我们能做什么? 读书/向认识的咨询专家在哪-向专家请求/
有搜索引擎的利好,让整个数字化的流程大大加速。 回到我们的搜索场景, 其实是本地化的, 本地化的搜索逻辑基本上是 利用全文搜索去解决如ELK/confluence。
我们再看看全文搜索的问题, 通过关键词去找关联, 会存在2个问题
- 关键词必须要匹配
- 关键词比较短的情况,搜索结果会特别大
那么怎么解决这个问题?
大模型,openai的大模型让我们看到了一个有理解能力和表达能力的超级知识体。
- 它掌握了几乎人类公开最精华的知识库了
- 它能够理解你的问题, 并基于它的知识库来组织语言回复你
上面描述的2个特性,完美的解决上面全文索引的问题, 在搜索引擎之后, 人类利用知识的效率达到一个新的高度。
其实如果使用大模型与大模型内部的知识库,其实很多什么只能解决通用性问题, 一旦问题涉及到自己的业务领域, 此时就需要把自己业务领域的知识喂给大模型。但是这里涉及几个问题
- 业务领域数据属于公司自有数据,全部喂给大模型,有数据泄露风险
- 大模型有token限制 , 目前的GPT-3.5-tubo-16K的限制是16k。 (业务领域的知识远远大于这个数字)
那怎么解决上面的问题呢?
llamada-index
使用Llamaindex连接大模型和本地知识库
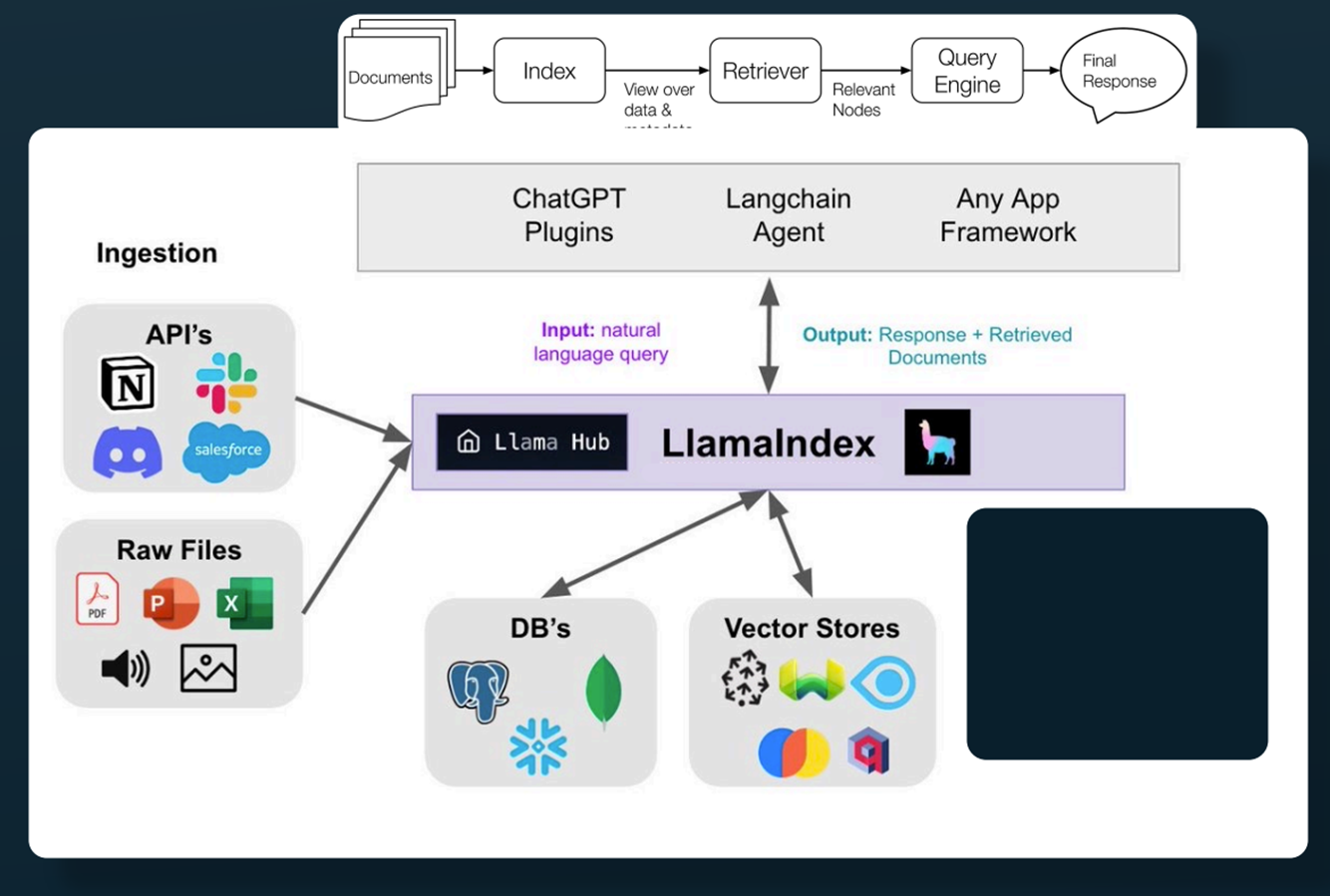
llamaIndex 处理什么问题?
提供一系列工具去方便用户去使用llm去调用本地知识库
工具包含: 对于各种大模型的封装 / 对于各种本地知识库的文件文件解析 / embedding模型的支持 / 向量数据库连接的封装
典型流程
- 用户问了一个问题
- llamda-index将用户问题(转化为向量)与本地知识库(向量数据库存储) 匹配, 搜索出Top-k 的相关文件片段
- llamad-index 将搜索用户问题 + 搜索出的相关文件片段 发送给大模型
- 大模型给出答复
showcode
本地文档如下-markdown文件
### 运维常用联系人 svn负责人: xxx1 gitlab负责人: xxx2 sonarqube负责人: xxx3代码如下
import os from langchain.llms import OpenAIChat # 这一步可以不需要,可以把OPENAI_API_KEY 放在环境变量里 # os.environ["OPENAI_API_KEY"] = '' from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage, \ LLMPredictor, ServiceContext if __name__ == "__main__": llm_predictor = LLMPredictor(llm=OpenAIChat(model_name="gpt-3.5-turbo-16k-0613", temperature=0.6, verbose=True)) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) if os.path.exists("./storage"): # rebuild storage context storage_context = StorageContext.from_defaults(persist_dir='./storage') # load index index = load_index_from_storage(storage_context, service_context=service_context) else: # 这步会解析documents目录下的文件。 把文件放在documents目录下(支持txt,md,docx,pdf..) documents = SimpleDirectoryReader('documents').load_data() # 这里会把解析后的文本内容,到openai获取embeddings数据(需要访问openai) index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context) # 解析文件后的数据存储到 storage目录下, 下次就不要再去解析 index.storage_context.persist() # 开始查询 query_engine = index.as_query_engine() # (需要访问openai) res = query_engine.query("<svn有问题需要找谁?>") print(res) #回复是: # svn有问题需要找artifactory/svn运维人员xxx2整个代码最终目标是产生prompt
Context information is below. --------------------- 运维过程常用联系人 gitee/gitlab运维: xxx1 artifactory/svn运维: xxx2 --------------------- Given the context information and not prior knowledge, answer the question: <svn有问题需要找谁?>答复
svn有问题需要找artifactory/svn运维人员xxx1
总结来说: 通过openai的embedding将文本转化成向量 ,然后存入向量数据库, 然后通过向量相关性来找出相关的高文档片段作为上下文, 加上问题一起发送给大模型,获得最终结果
整个流程核心点:
- openai的embedding接口
- 向量数据库求top-n
引入向量数据库的必要性
- 再回到全文索引的关键字搜索的两个问题
关键词绝对匹配
关键词比较短的情况,搜索结果会特别大
举个例子我们搜索elk相关问题时, 如果我们搜索的问题中包含logstash, 假设你的文档里不包含logstash这个关键词,但包含elk这个词时。 那么关键字搜索时搜不到相关的文章。 此时如果用借助向量数据库, logstash 与 elk 这两个词在openai-embedding模型里是必然有相关性的,那么它就能把相关连的文档搜出来, 然后再借助大模型的语言组织能力给你一个跟文档相关的答案。 引入了向量数据库,关键词绝对匹配的问题就不存在了。
由于大模型有理解能力, 那么你在搜索问题时,其实像和人类一样问题就变的自然了,完整表达自己的问题就好了。
- 当然引入向量库主要的原因是token限制。 如果未来大模型没有token限制, 向量数据库在这个流程里就没有存在必要。
开源模型支持
还有一个问题时数据泄密问题。 这个llamda-index其实是支持开源的模型的。 整个流程里与openai有交互的有两个
- embedding 求文本的向量
- 给大模型问题, 让大模型给出答复
对应的解决办法
- 使用Langchain的的embedding模型
- LLMPredictor 可以换成 HuggingFaceLLMPredictor
还需要解决的问题
通过上面的小demo, 我们能初步实现大模型和本地知识库的连接
当然还有很多其他的问题
日常文档里,其实有很多截图类的东西
这个目前的话,llmada-index目前在解析文档时会把图片,链接去掉 , 那么其实求相关还是问题和文档文本的相关性。 图片信息内容就丢失了
当问题得到回复时,我们还是想看完整文档, 这个需要对文档做个关联索引
如果你的业务足够垂直的话,其实openai的embedding也是不够好的。那么关联性就不够好.
这块可能需要找领域相关的embedding模型来替代
怎么将业务的知识库和问答系统中间的流程自动化
知识库收集标准
知识库收集后的embedding和建立文档索引