
案例分析-sysbench压测MySQL时kill连接后为什么不会重连
重现
- 机器环境 Aliyun ALinux3 OS镜像


重现步骤
客户端和服务端可以在一台机器里
安装客户端sysbench
yum install sysbench -y # sysbench --version sysbench 1.0.20 # 宿主机上安装MySQL Client命令行,方便调试: yum install mysql.x86_64 -y服务端
# 安装docker yum install -y java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 podman-docker.noarch wireshark docker run -it -d --net=host -e MYSQL_ROOT_PASSWORD=123 --name=mysqlserver mysql:5.7.32执行步骤 准备
通过MySQL Client命令行连接进入MySQL
mysql -h127.1 --ssl-mode=DISABLED -utest -p123创建一个测试库
mysql -h127.1 --ssl-mode=DISABLED -uroot -p123 -e "create database test"随机生成数据
sysbench --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3306' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='1180' --report-interval='1' --histogram='on' --threads=1 oltp_read_only prepare
重现步骤
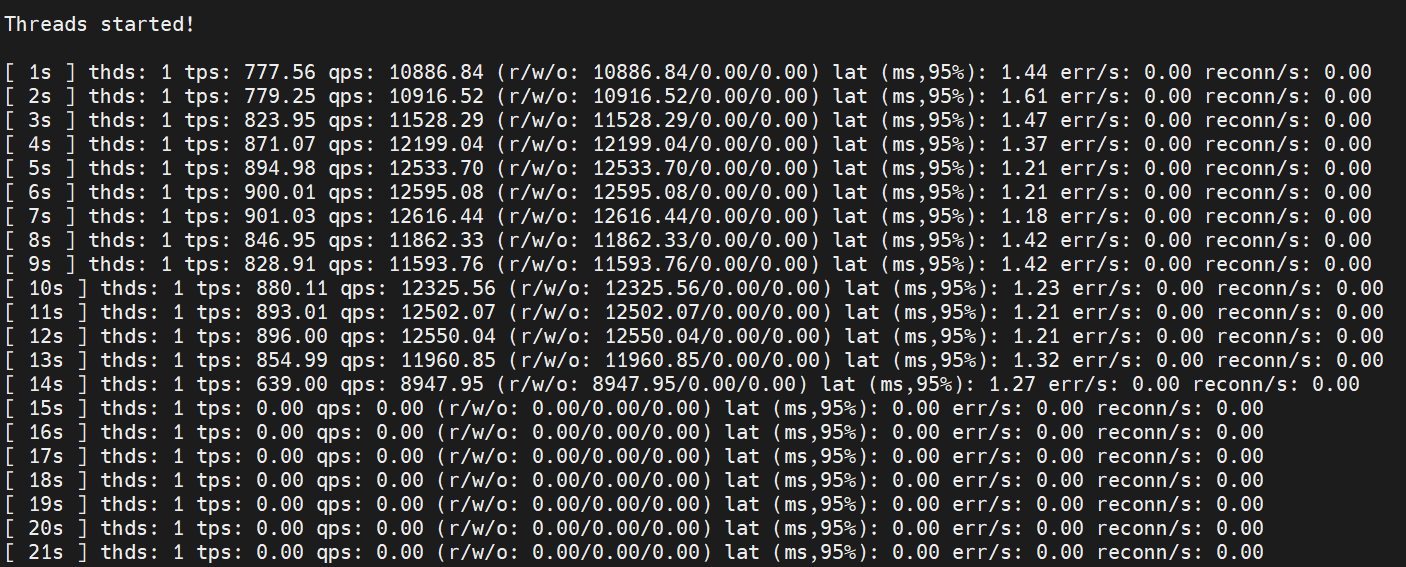
启动压力(只用一个线程):
sysbench --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3306' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='1180' --report-interval='1' --histogram='on' --threads=1 oltp_read_only run登录mysql kill sysbench 连接
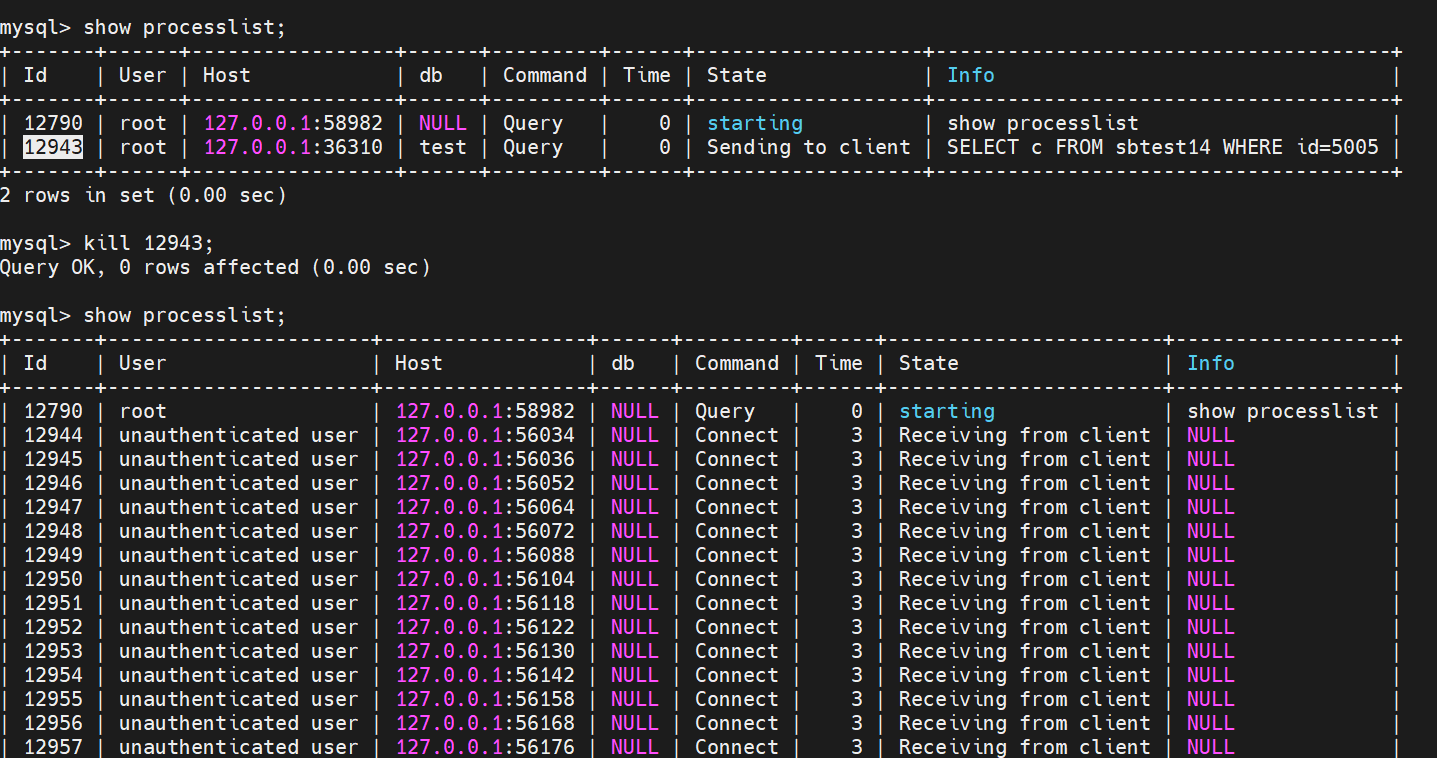
mysql -h127.1 --ssl-mode=DISABLED -uroot -p123 test show processlist; kill xxxxx
重现现象
qps
mysql server
自己的分析
收集数据
在kill 前就要开始抓数据 , 提前准备好命令
top
strace 客户端
strace -tt -T -v -f -o strace_client_killing.log -s 1024 -p 2127123strace 服务端
strace -tt -T -v -f -o strace_mysqld_killing.log -s 1024 -p 1932245抓包
tcpdump -i lo -w 20240404.cap
初步看下
sysbench 占用cpu较高
我们待会可以通过strace 看看到底在干嘛
- 可以看下kill 之前的cpu来作为对比
看下tcp连接
ss -s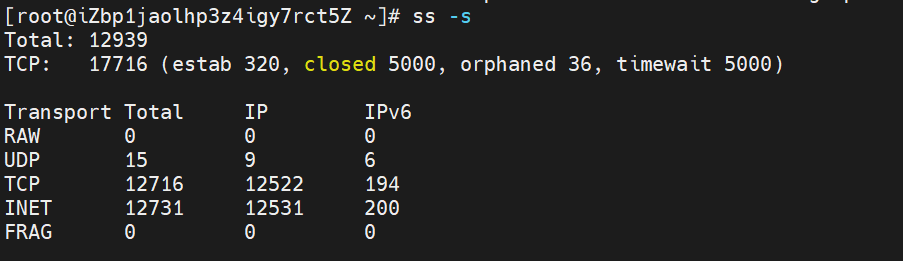
lsof -p sysbench-pid
有大量和mysql的连接 但是状态大部分都是CLOSE_WAIT
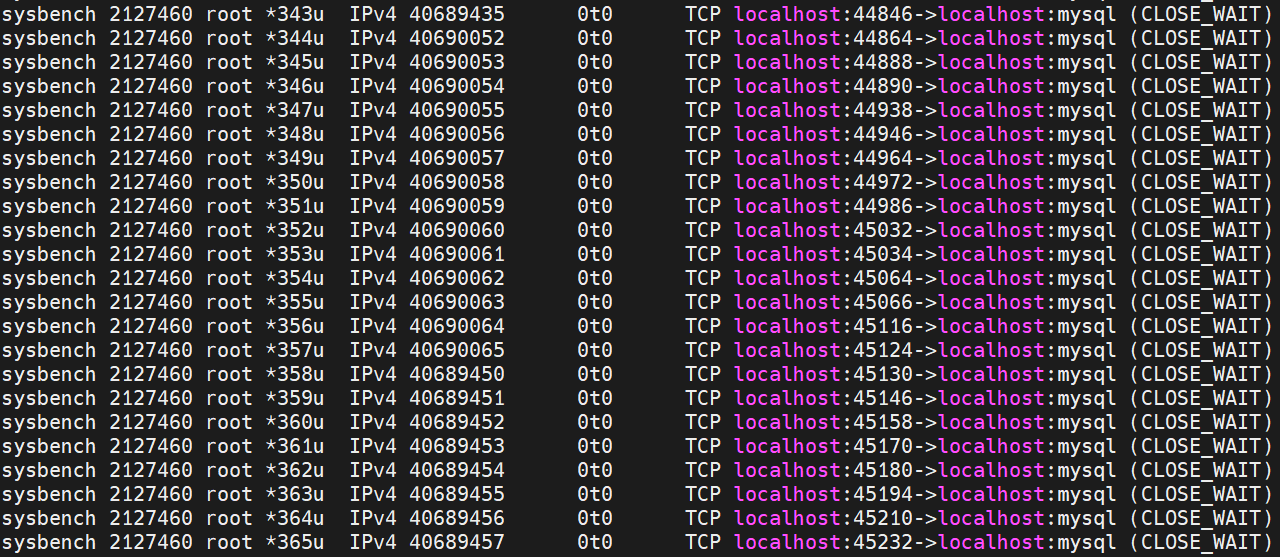
分析strace
通过初步分析大概的结论就是sysbench 连接被kill掉之后, 就再也连不上了, 但是它还是疯狂的连接
分析客户端strace
找到kill的点 就是没有recvfrom的调用后的第一次connect
从那之后 sysbench 一直在尝试 connect 但是一直没有后续的交互 (没有close,没有recvfrom对应的socket)
2068703 22:37:46.266021 recvfrom(3, “\1\0\0\1\1,\0\0\2\3def\4test\10sbtest10\10sbtest10\1c\1c\f-\0\340\1\0\0\376\1\0\0\0\0\5\0\0\3\376\0\0\2\0x\0\0\4w44163145631-40711675811-29769759458-52841809523-32142595466-20390295316-16081138094-83491156968-96170060788-60131956603\5\0\0\5\376\0\0\2\0”, 16384, MSG_DONTWAIT, NULL, NULL) = 195 <0.000023>
2068703 22:37:46.266110 sendto(3, “%\0\0\0\3SELECT c FROM sbtest10 WHERE id=4993”, 41, MSG_DONTWAIT|MSG_NOSIGNAL, NULL, 0) = 41 <0.000142>
2068703 22:37:46.266416 recvfrom(3, “\1\0\0\1\1,\0\0\2\3def\4test\10sbtest10\10sbtest10\1c\1c\f-\0\340\1\0\0\376\1\0\0\0\0\5\0\0\3\376\0\0\2\0x\0\0\4w06347384985-74197502335-75472109144-17537175997-80772785336-15693313337-07147118123-97137896436-42800179990-30979180332\5\0\0\5\376\0\0\2\0”, 16384, MSG_DONTWAIT, NULL, NULL) = 195 <0.000052>
2068703 22:37:46.266527 sendto(3, “%\0\0\0\3SELECT c FROM sbtest10 WHERE id=4983”, 41, MSG_DONTWAIT|MSG_NOSIGNAL, NULL, 0) = 41 <0.000049>
2068703 22:37:46.266615 recvfrom(3, “”, 16384, MSG_DONTWAIT, NULL, NULL) = 0 <0.000020>
2068703 22:37:46.266677 close(3) = 0 <0.000026>
2068703 22:37:46.266751 getpid() = 2068701 <0.000020>
2068703 22:37:46.266824 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3 <0.000027>
2068703 22:37:46.266885 fcntl(3, F_SETFL, O_RDONLY|O_NONBLOCK) = 0 <0.000021>
2068703 22:37:46.266938 connect(3, {sa_family=AF_INET, sin_port=htons(3306), sin_addr=inet_addr(“127.0.0.1”)}, 16) = -1 EINPROGRESS (Operation now in progress) <0.000083>
2068703 22:37:46.267165 poll([{fd=3, events=POLLOUT}], 1, -1) = 1 ([{fd=3, revents=POLLOUT}]) <0.000023>
2068703 22:37:46.267227 getsockopt(3, SOL_SOCKET, SO_ERROR, [0], [4]) = 0 <0.000020>
2068703 22:37:46.267283 fcntl(3, F_SETFL, O_RDONLY) = 0 <0.000020>
2068703 22:37:46.267356 clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=0, tv_nsec=1000000}, NULL) = 0 <0.001084>
2068703 22:37:46.268482 getpid() = 2068701 <0.000020>
2068703 22:37:46.268546 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 4 <0.000026>
2068703 22:37:46.268602 fcntl(4, F_SETFL, O_RDONLY|O_NONBLOCK) = 0 <0.000020>
2068703 22:37:46.268653 connect(4, {sa_family=AF_INET, sin_port=htons(3306), sin_addr=inet_addr(“127.0.0.1”)}, 16) = -1 EINPROGRESS (Operation now in progress) <0.000065>
2068703 22:37:46.268848 poll([{fd=4, events=POLLOUT}], 1, -1) = 1 ([{fd=4, revents=POLLOUT}]) <0.000022>
2068703 22:37:46.268907 getsockopt(4, SOL_SOCKET, SO_ERROR, [0], [4]) = 0 <0.000020>
2068703 22:37:46.268962 fcntl(4, F_SETFL, O_RDONLY) = 0 <0.000020>
2068703 22:37:46.269020 clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=0, tv_nsec=1000000}, NULL) = 0 <0.001087>
2068703 22:37:46.270146 getpid() = 2068701 <0.000020>
2068703 22:37:46.270201 mprotect(0x7f4710035000, 8192, PROT_READ|PROT_WRITE) = 0 <0.000026>
2068703 22:37:46.270268 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 5 <0.000024>
分析服务端strace
- 不断的accept 新连接
从下面的accept 发现 也在一直建立新的socket
但是他还是发送了数据 sendto(65 而且也能在10s后搜到close(65)
1937180 05:47:57.345796 close(65 <unfinished …>
1932245 05:47:47.334761 accept(21, {sa_family=AF_INET6, sin6_port=htons(37504), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, “::ffff:127.0.0.1”, &sin6_addr), sin6_scope_id=0}, [128 => 28]) = 65 <0.000021>
1932245 05:47:47.334823 futex(0x561abd48fb88, FUTEX_WAKE_PRIVATE, 1 <unfinished …>
1937180 05:47:47.334858 <… futex resumed>) = 0 <2.014108>
1932245 05:47:47.334869 <… futex resumed>) = 1 <0.000039>
1937180 05:47:47.334884 futex(0x561abd48fba0, FUTEX_WAIT_PRIVATE, 2, NULL <unfinished …>
1932245 05:47:47.334893 futex(0x561abd48fba0, FUTEX_WAKE_PRIVATE, 1 <unfinished …>
1937180 05:47:47.334902 <… futex resumed>) = -1 EAGAIN (Resource temporarily unavailable) <0.000012>
1932245 05:47:47.334914 <… futex resumed>) = 0 <0.000015>
1937180 05:47:47.334923 futex(0x561abd48fba0, FUTEX_WAKE_PRIVATE, 1 <unfinished …>
1932245 05:47:47.334933 poll([{fd=21, events=POLLIN}, {fd=22, events=POLLIN}], 2, -1 <unfinished …>
1937180 05:47:47.334945 <… futex resumed>) = 0 <0.000017>
1937180 05:47:47.334987 setsockopt(65, SOL_TCP, TCP_NODELAY, [1], 4) = 0 <0.000019>
1937180 05:47:47.335042 gettid() = 353 <0.000018>
1937180 05:47:47.335090 getpeername(65, {sa_family=AF_INET6, sin6_port=htons(37504), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, “::ffff:127.0.0.1”, &sin6_addr), sin6_scope_id=0}, [128 => 28]) = 0 <0.000019>
1937180 05:47:47.335145 setsockopt(65, SOL_SOCKET, SO_KEEPALIVE, [1], 4) = 0 <0.000019>
1937180 05:47:47.335195 getpid() = 1 <0.000018>
1937180 05:47:47.335242 getpid() = 1 <0.000018>
1937180 05:47:47.335288 getpid() = 1 <0.000017>
1937180 05:47:47.335365 sendto(65, “J\0\0\0\n5.7.32\0\252\37\0\0c3M%.lN\30\0\377\377\10\2\0\377\301\25\0\0\0\0\0\0\0\0\0\0=\16\25o7k[D\7\26’B\0mysql_native_password\0”, 78, MSG_DONTWAIT, NULL, 0) = 78 <0.000028>
1937180 05:47:47.335437 recvfrom(65, 0x7f4230099eb0, 4, MSG_DONTWAIT, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable) <0.000018>
1937180 05:47:47.335486 poll([{fd=65, events=POLLIN|POLLPRI}], 1, 10000 <unfinished …>
1932245 05:47:47.335838 <… poll resumed>) = 1 ([{fd=21, revents=POLLIN}]) <0.000896>
1932245 05:47:47.335872 accept(21, {sa_family=AF_INET6, sin6_port=htons(37506), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, “::ffff:127.0.0.1”, &sin6_addr), sin6_scope_id=0}, [128 => 28]) = 66 <0.000021>
1932245 05:47:47.335937 futex(0x561abd48fb88, FUTEX_WAKE_PRIVATE, 1 <unfinished …>
1957257 05:47:47.335969 <… futex resumed>) = 0 <2.015047>
1932245 05:47:47.335979 <… futex resumed>) = 1 <0.000035>
1957257 05:47:47.335996 futex(0x561abd48fba0, FUTEX_WAIT_PRIVATE, 2, NULL <unfinished …>
1932245 05:47:47.336004 futex(0x561abd48fba0, FUTEX_WAKE_PRIVATE, 1 <unfinished …>
1957257 05:47:47.336017 <… futex resumed>) = -1 EAGAIN (Resource temporarily unavailable) <0.000016>
1932245 05:47:47.336030 <… futex resumed>) = 0 <0.000020>
第二阶段 too many connects
mysqld服务是有max_connections。 默认值是150
所以第二阶段能看到 Too many connections
1932245 05:47:47.501823 sendto(214, “\27\0\0\0\377\20\4Too many connections”, 27, MSG_DONTWAIT, NULL, 0) = 27 <0.000042>
看看抓包
看了前面的strace数据 其实我也没得到确切的结论是谁的问题

通过上图能看到(和mysqld的strace结果吻合) 断开连接是 mysql端在10s后做出的 。 那么是mysql的问题么?
这时候需要对比一下正常的连接是什么样的
mysql -h127.1 --ssl-mode=DISABLED -utest -p123 -e "select 1"
tcpdump -i lo -w normal_mysql_connect_nossl.cap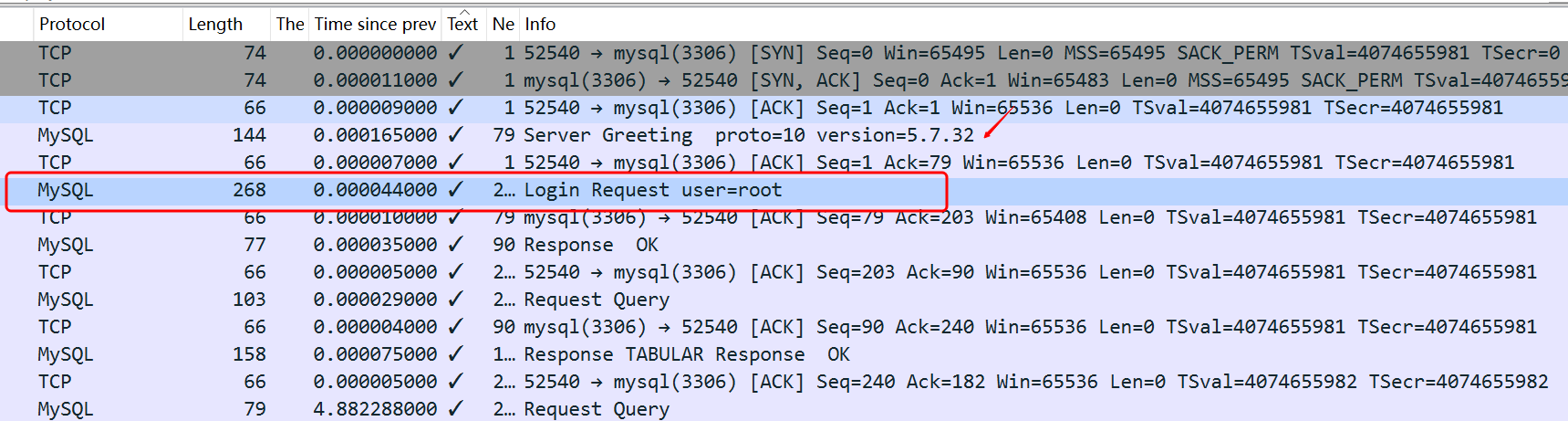
可以看到 mysql server greeting后 其实需要客户端发送 用户名等数据
那么此时我可以确定是sysbench的问题。
但是为什么sysbench就连不上了呢?
我也确认了 ulimit -a 看了下openfiles 是65536 。 sysbench 占用没有超过这个值。
好了我分析就到此。 那么下一步我们结合大佬的分析来复盘 我哪里有问题。
我的疑问其实没有解答:
为什么sysbench尝试连接连不上了呢?
为什么cpu升高
为什么有这么多TIMEWAIT
@plantegg的分析复盘
来自 https://wx.zsxq.com/dweb2/index/group/15552551584552 这里强烈推荐下@plantegg的 星球
程序员踩坑案例分享
ss -s 发现有很多连接 不正常
看下状态
结论: 注意第二列Recv-Q一直都是79,Recv-Q的意思是3306端发给Sysbench的内容79字节,但这79自己还在 OS 的tcp buffer 中,等待Sysbench 读走。
能判断是sysbench的问题
# netstat -anto | head -30 //确实可以看到几万个连接,几乎都是 CLOSE_WAIT 状态
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State Timer
tcp 79 0 192.168.0.1:48743 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0)
tcp 79 0 192.168.0.1:32747 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0)
tcp 79 0 192.168.0.1:40838 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0)
tcp 79 0 192.168.0.1:40190 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0)
tcp 79 0 192.168.0.1:58337 192.168.20.220:3306 CLOSE_WAIT off 确认下为什么sysbench没有读走这些消息
源码分析
```c
//connect()时进行随机端口四元组可用性的判断
//如果本地地址和目标地址组成的元组之前已经存在了,则返回错误码EADDRNOTAVAIL: Cannot assign requested address
//这个时候即使设置了REUSEADDR也要报错
/* called with local bh disabled */
static int __inet_check_established(struct inet_timewait_death_row *death_row,
struct sock *sk, __u16 lport,
struct inet_timewait_sock **twp)
{
struct inet_hashinfo *hinfo = death_row->hashinfo;
struct inet_sock *inet = inet_sk(sk);
__be32 daddr = inet->inet_rcv_saddr;
__be32 saddr = inet->inet_daddr;
int dif = sk->sk_bound_dev_if;
struct net *net = sock_net(sk);
int sdif = l3mdev_master_ifindex_by_index(net, dif);
INET_ADDR_COOKIE(acookie, saddr, daddr);
const __portpair ports = INET_COMBINED_PORTS(inet->inet_dport, lport);
unsigned int hash = inet_ehashfn(net, daddr, lport,
saddr, inet->inet_dport);
//inet_ehash_bucket存放ESTABLISHED状态的socket 哈希表
struct inet_ehash_bucket *head = inet_ehash_bucket(hinfo, hash);
spinlock_t *lock = inet_ehash_lockp(hinfo, hash);
struct sock *sk2;
const struct hlist_nulls_node *node;
struct inet_timewait_sock *tw = NULL;
spin_lock(lock);
//遍历检查四元组是否冲突
sk_nulls_for_each(sk2, node, &head->chain) {
if (sk2->sk_hash != hash)
continue;
//INET_MATCH 执行四元组比较
if (likely(INET_MATCH(sk2, net, acookie,
saddr, daddr, ports, dif, sdif))) {
if (sk2->sk_state == TCP_TIME_WAIT) {
tw = inet_twsk(sk2);
if (twsk_unique(sk, sk2, twp))
break;
}
goto not_unique;
}
}
……
not_unique:
spin_unlock(lock);
return -EADDRNOTAVAIL; //Cannot assign requested address错误,在510行看到了下一节 telnet/strace 中的错误信息
```到这里可以很清楚说明问题在客户端而不是服务端,但是要回答:
- 为什么CPU这么高,CPU都在忙什么
- 什么原因会导致 CLOSE_WAIT 状态
- 为什么Sysbench 要疯狂创建4万多个连接;
为什么CPU这么高,CPU都在忙什么
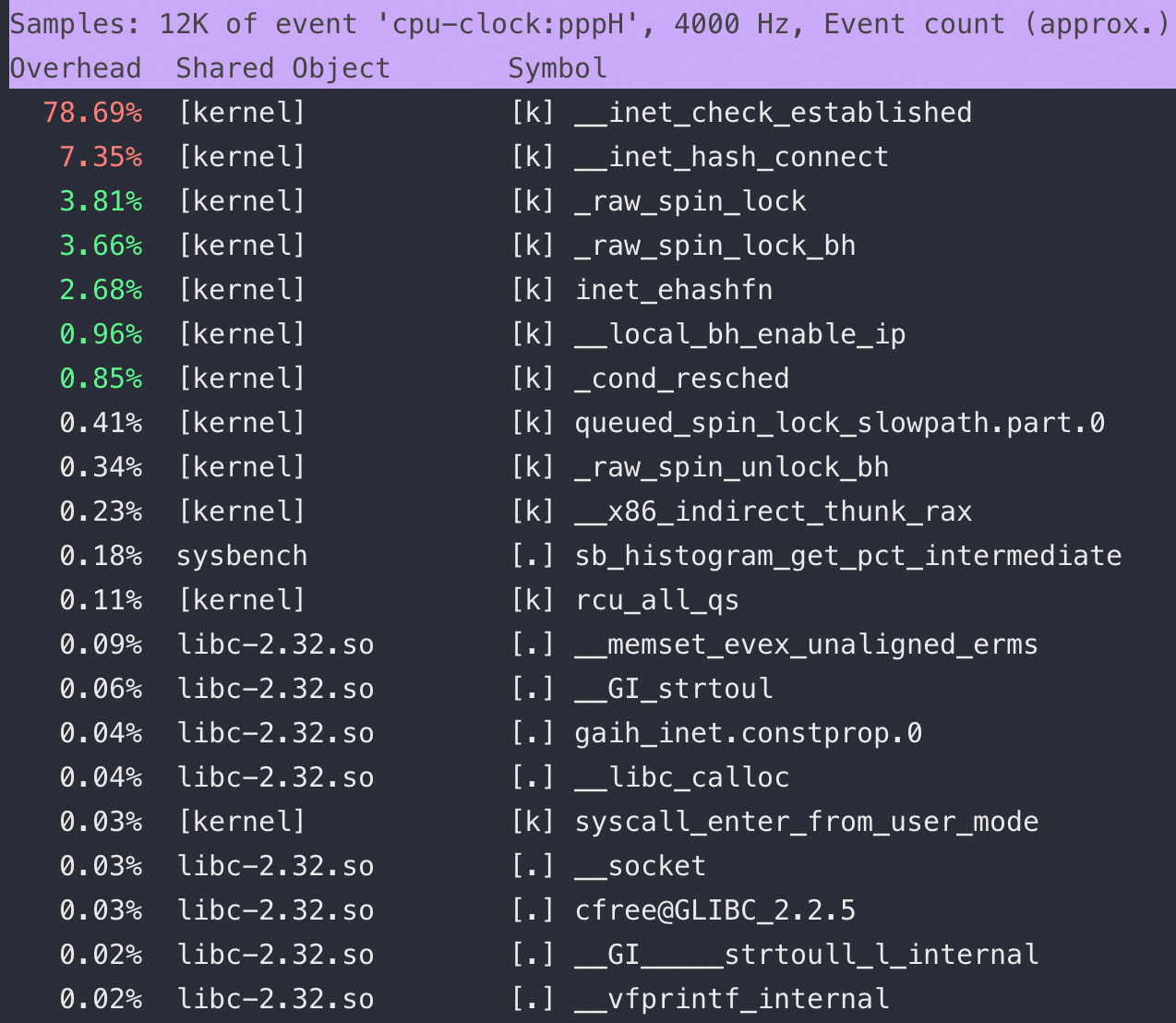
首先用 strace -p Sysbench-pid 看看 Sysbench 进程都在忙什么,下图最上面是 Sysbench 在疯狂不断地 connect:
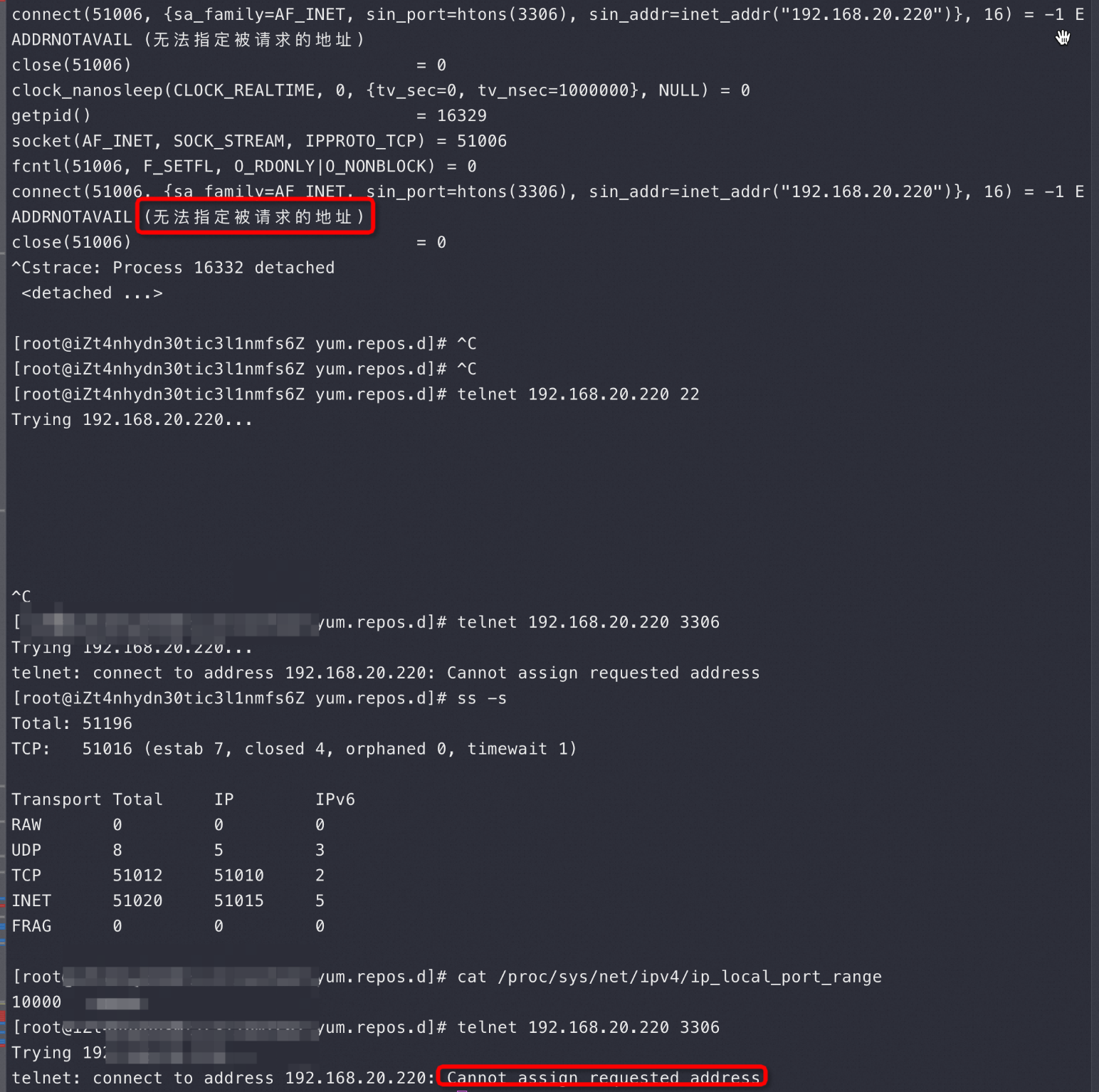
从上图最上面的Strace 来看 Sysbench在疯狂创建连接,但是在Connect 的时候报错:无法指定被请求的地址
到这里,很多人卡在了strace 没有输出,这里其实算我故意留下的一个小坑,我第一次也卡这里了,怎么没有输出呢?Sysbench跑起来后是多个线程,默认没有输出那个应该是主线程,还有很多线程负责压力,我是怎么反应过来的呢 top -Hp sysbench-pid 可以看到多个线程,然后找CPU 消耗高的那个 线程 id 去strace
那接下来我就要ping 一下 192.168.20.220 这个IP 是OK的,再然后telnet 192.168.20.220 22 发现没报错但是也没有 SSH 让我输密码,于是看了下 cat /proc/sys/net/ipv4/ip_local_port_range 是4万个Local Port 可用,这个时候可以去看看我这篇关于可用端口的经典文章
于是我改了下Port Range范围多加了1万Port 上去,然后很快看到如图 ss -s 就有5万连接了,说明你给多少Port 都不够用
同时我也用 telnet 192.168.20.220 3306 报错是:Cannot assign requested address —— 这个报错和 无法指定被请求的地址 很像了,到这里可以看到做一个基本结论:
- 之所以内核 sys CPU 跑高到 100%,是因为当Local Port 用完,又要新建连接的时候内核会用死循环去找可用端口,导致CPU 跑高(这也是为什么telnet 22端口不会报错,也不会正常出来SSH login——因为抢不到CPU 资源)
- Cannot assign requested address 和 无法指定被请求的地址 报错都是找不到可用端口导致的,还没有走到三次握手,也就是和服务端无关
继续折腾验证:
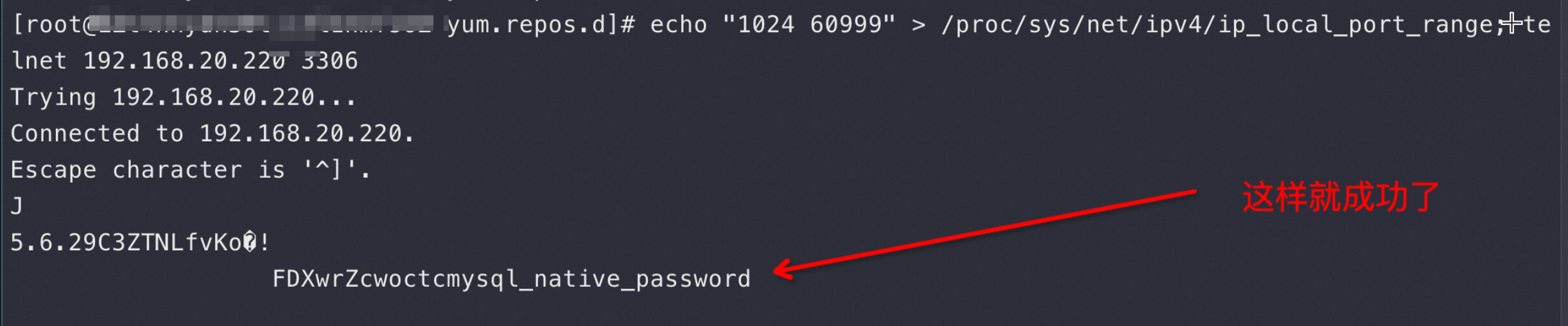
先把local port 增多,然后立即 telnet 3306 发现成功了!这更是证明了上面的结论2
到这里分析清楚了为什么CPU 高—— Sysbench疯狂建连接导致端口用完,内核要用死循环不断去找可用端口导致了CPU使用率高,因为是内核态的行为所以表现出来就是 sys CPU 100%
而telnet 22端口不报这个错,是因为 22端口的可用端口几万个没有被使用掉,但是22端口也没让我输密码,这里应该是telnet 22时抢不到CPU 造成TCP 三次握手缓慢(可以抓包验证,略),但绝对不会报 Cannot assign requested address 错误
什么原因会导致 CLOSE_WAIT 状态
在讲这个问题前还是请先去看看 CLOSE_WAIT 代表了什么含义: 为什么这么多CLOSE_WAIT
当同事们看到几万个连接的时候第一反应就是能不能改改这两 Linux 的系统参数:tcp_tw_reuse, tcp_tw_recycle 让端口/连接快速回收?
有没有你们就是这种同事,看到一个现象条件反射得出这个结论,这都是略知皮毛的经验太多了导致的
我在 《为什么这么多CLOSE_WAIT》一文中反复提到这张图,以及学霸是怎么从这张图推断原因的:
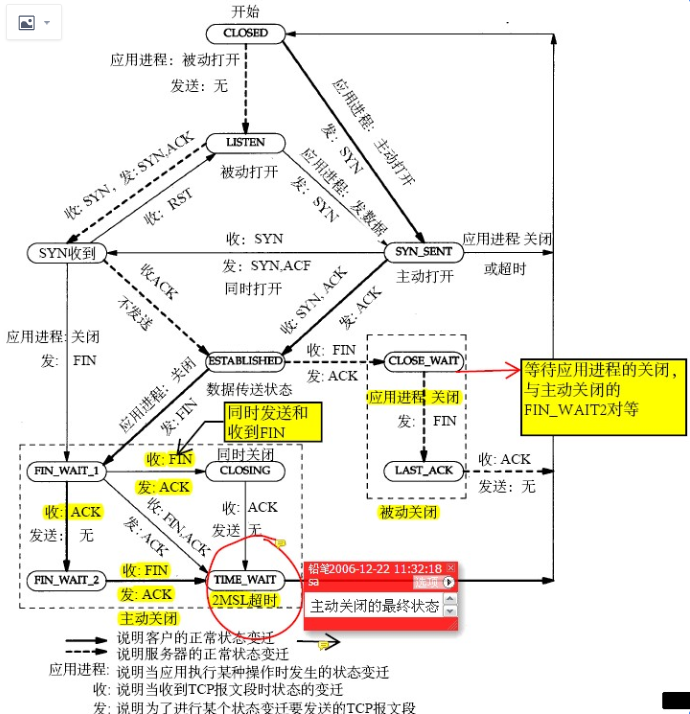
看完上面这个图和我的 《为什么这么多CLOSE_WAIT》就应该知道 CLOSE_WAIT 就是 Sysbench 没有调 Socket.close 导致的 和内核没有关系,所以改啥内核参数也没有用,真正理解好基础知识才不会瞎折腾
如何进一步证明是Sysbench的问题呢?这又回到了我们的老本行抓包:

上图是在 Sysbench 所在ECS 上抓包可以看到大量这样的连接,注意第四个包是 Server端在3次握手成功后发了 Server Greeting 给Sysbench,此时Sysbench应该发自己的账号密码来 Login但是抓包永远卡在这里,也就是Sysbench 建立完连接后跑了,不搭理服务端发了什么,这也是为什么最前面的 netstat -anto 看到 Recv-Q 这列总是79,这79长度的内容就是 Server 发给Sysbench 的 Server Greeting 内容,应该Sysbench去读走然后按照MySQL 协议发账号密码,但是不,此时Sysbench 颠了,不管这个连接了,又去创建新连接于是重复上面的过程;直到本地端口用完,sys CPU 干到 100%
其实上面这个抓包的连接状态是 ESTABLISHED 状态,为什么最终看到的是 CLOSE_WAIT 呢,因为 Server发了 Server Greeting 后有一个超时时间,迟迟等不到Sysbench Client的账号密码就会发fin 给Client 端请求断开这个连接,导致Client断的连接状态从 ESTABLISHED 进入 CLOSE_WAIT ,这从上面的 TCP 状态图完全可以推导出来,扩大抓包时间的话会抓到 Server 发过来的 fin包
你要看不懂这个抓包,可以找个正常的MySQL-client 连 Server抓一次包,有个正常的对比会很幸福,我丢一个正常的给大家对比参考,上面错在 Sysbench 没有发如下红框的包:
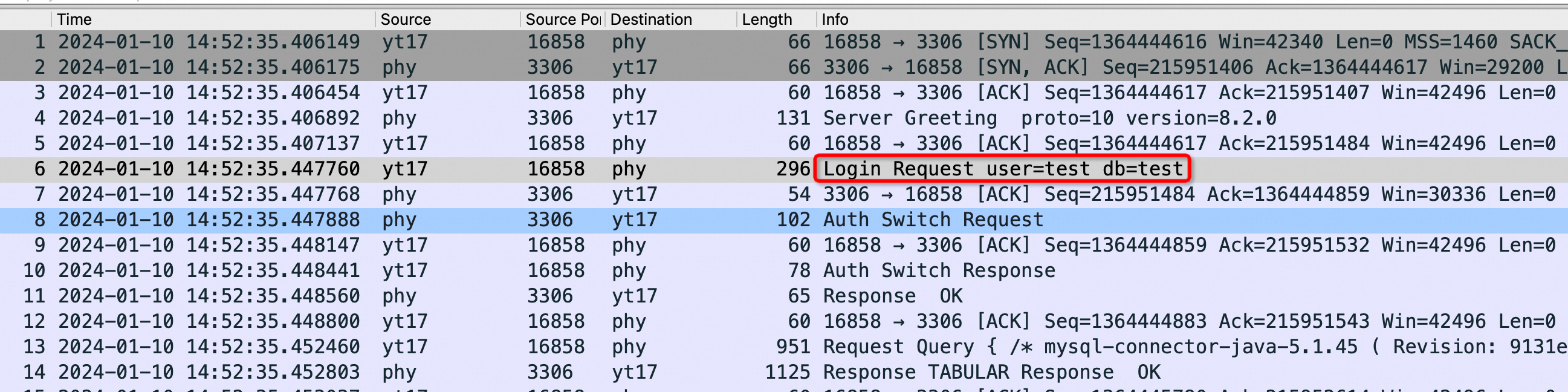
Server 一重启就去看 netstat 的话确实都是 ESTABLISHED:
# netstat -anto | head -30 |grep -E “State|:3306 “
Proto Recv-Q Send-Q Local Address Foreign Address State Timer
tcp 78 0 192.168.0.1:46344 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:44592 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:45908 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:44166 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:59484 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:60720 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:53436 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:58690 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:35932 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:53944 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:59758 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:53676 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:59304 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:41848 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:44312 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:56654 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:3516 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:39316 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:55074 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:59476 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
tcp 78 0 192.168.0.1:48854 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
此时端口还够的时候去strace 看到Sysbench 确实在疯狂 connect 建连接,也不像端口不够的时候会报错:
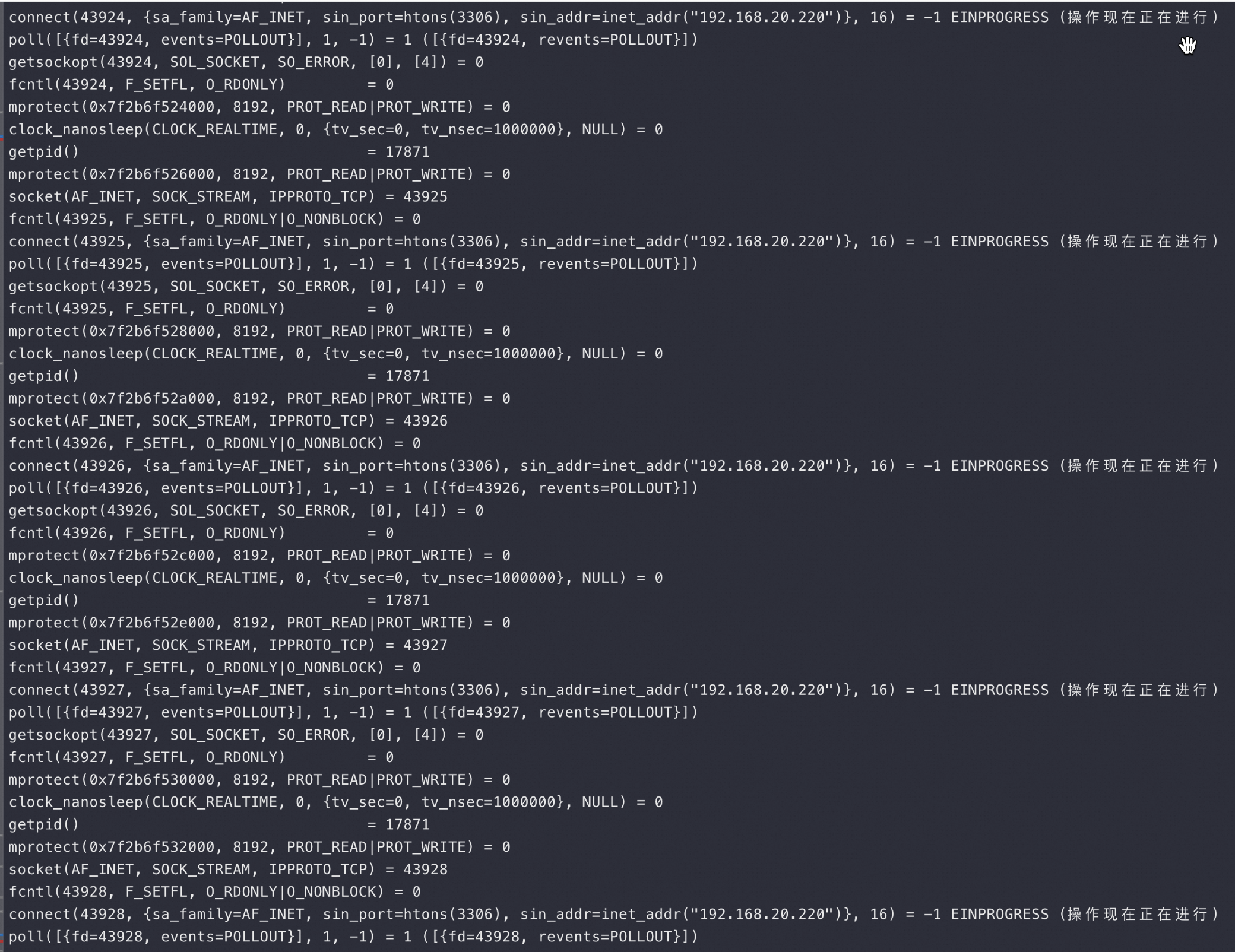
到这里就可以回答:什么原因会导致 CLOSE_WAIT 状态?因为Sysbench 没有去正常 Login MySQL,也没有调用 Socket.close 导致的
为什么Sysbench 要疯狂创建4万多个连接
为什么Sysbench 要疯狂创建4万多个连接,且还在不停地创建,这就要涉及到 Sysbench 具体代码逻辑(这个版本的 Sysbench 被我厂同事魔改过) ,在一猛子扎进去看代码逻辑前,我换了个开源的 Sysbench 版本,问题就消失了 —— 有时候猛干不去取巧
到此可以说明问题的原因就是:这个 Sysbench 版本在连接异常断开(Server升级主动断开连接)后,新建连接逻辑错误,疯狂建连接引起的
至于代码哪里错了我就没兴趣了
@邹扒皮.com的分析(TBC)
从 @plantegg的分析我们学到了
sysbench在忙什么以及把本地端口占满了。
但是还是不清楚为什么第一次重连为什么会连不上呢?(此时mysqld 最大连接也没满, 本地端口也够用)
这个属于用户态的逻辑了 只能通过源码来分析了