案例分析-服务上线后nginx-504的分析过程
背景
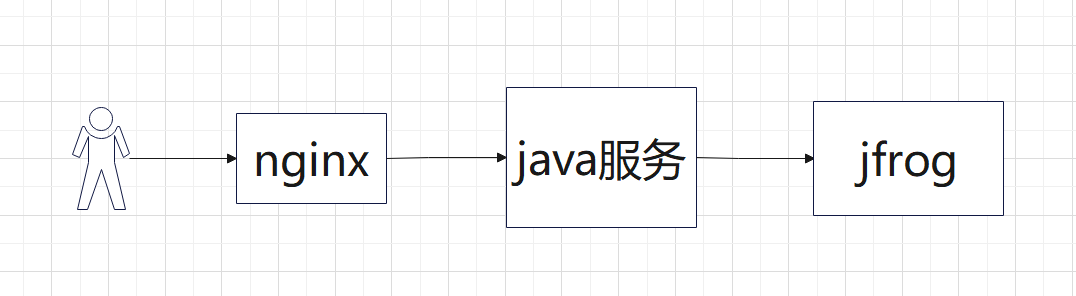
一个封装jfrog接口的文件管理工具, 因为高可用改造, 从单节点变成双节点,因为服务依赖分布式存储,也引入了炎融云存储
问题
用户上传一个26g的文件 每次快到3小时就504了, 之前没有遇到过
- 链路如下
分析
初步分析
504 Gateway 第一反应是后端服务执行超时了。 然后确认了下nginx proxy_read_timeout 5400s = 1.5hour
3小时大于1.5 。 不匹配
重现
研发同学说问题很好重现, 他的机器也有个26g的文件 , 于是趁着周末用的人少去重现了一把
这种问题就老老实实一个节点一个节点的去分析
nginx服务器
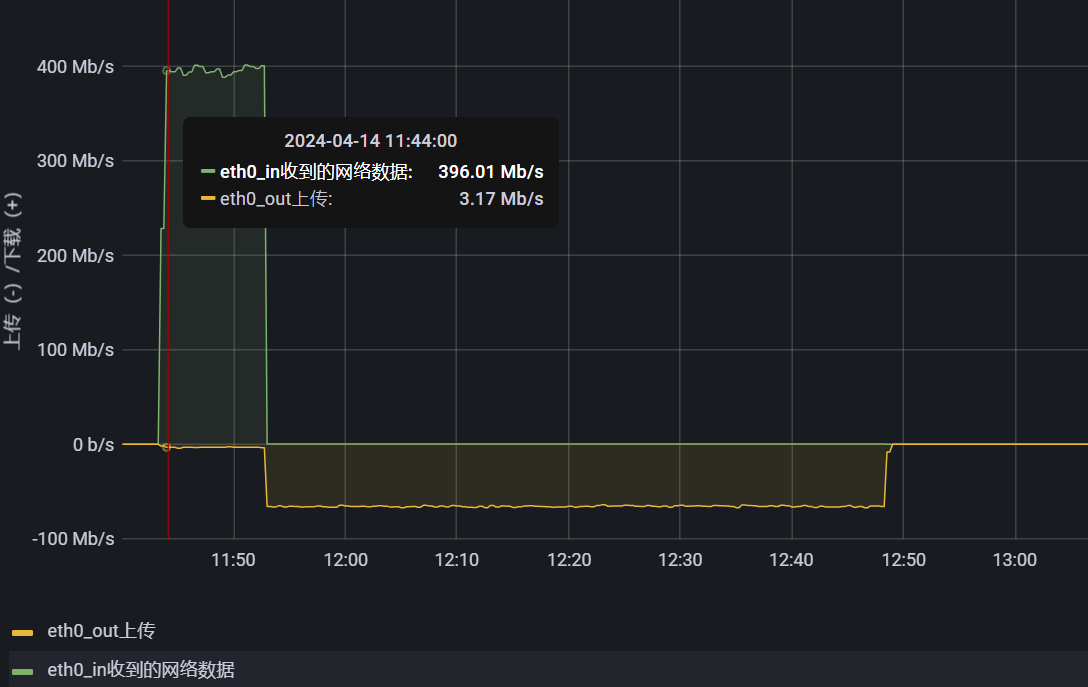
从上图能明显的看出来 用户上传用的时间很少 差不多9min, 11:52之后就是把收到的数据发送给java服务了
可以通过lsof 和 strace 命令来验证这个逻辑
upload to nginx temp

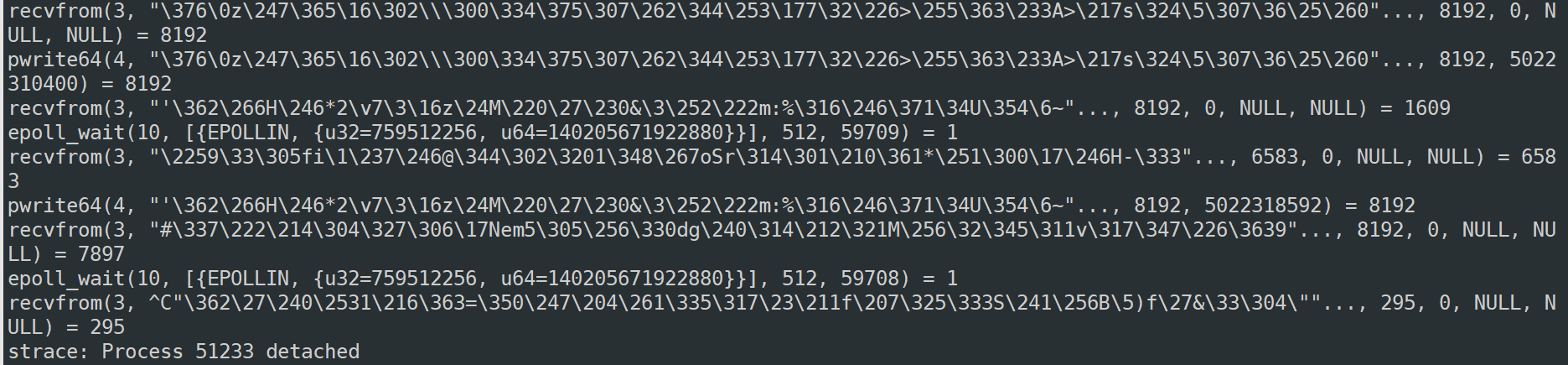
上面2张图表示 nginx 从file fd 3 读数据并写到 file fd 4 也就是nginx的临时目录文件
send to java server


sendfile - transfer data between file descriptors 这里使用的是sendfile. 和nginx的配置对应。 sendfile on; 上图能明显看出 temp 文件写完后,开始向java服务器传输数据 8u就是 nginx和java服务器之间建立socket连接描述符
java 服务
java server write file to temp file


可以看到 从read from 783 write to 790 tomcat的一个临时文件
save to upload directory , ready to upload jfrog


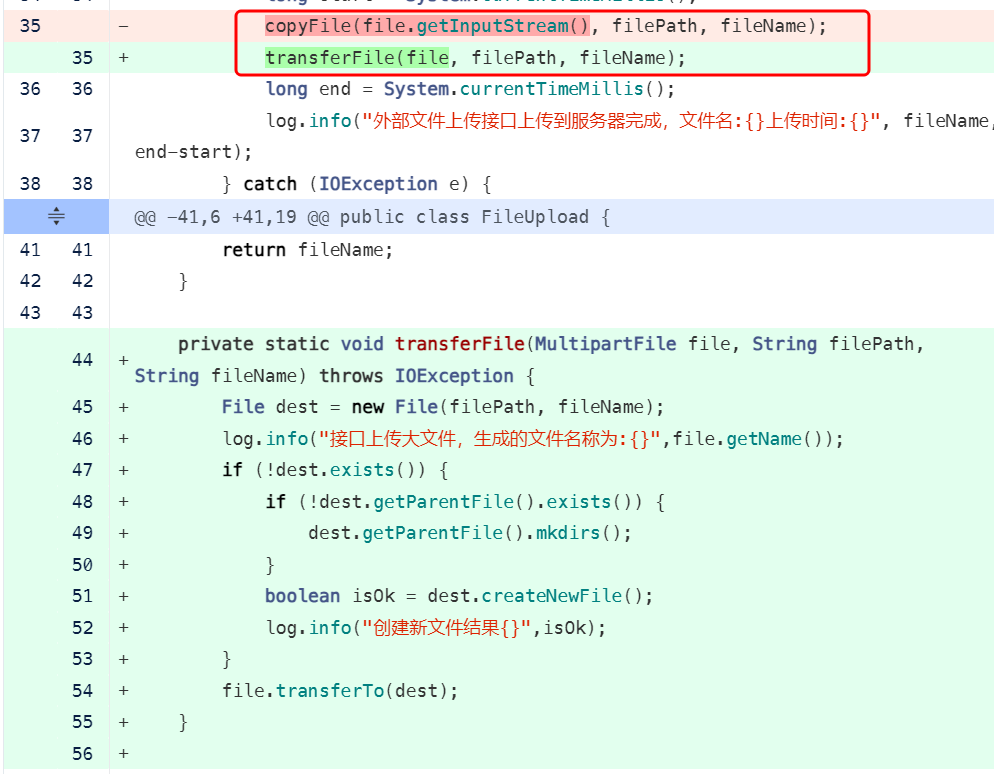
看到这里 这是我们可以了解到 java 收到文件先写到本地临时文件 然后有read & write 到 另外一个文件。首先这是不是合理的且不说。 因为之前了解到炎融云文件有性能问题 。 这里在这个文件服务里有3个io操作
write [1]-> read[2] -> write[3] 。 在1完成后, nginx 和 java 是没有数据交互的。 此时java做 2 和3 步骤。 如果 2和3 做的时间超过 proxy_read_timeout的1.5小时。 那么必然会出现 504
那么随后的抓包能确认这个事
nginx - java
nginx 在timeout 之后 主动发给java Fin 关闭连接, 25min之后 , java程序完成了文件写过程, 发送给nginx 200. 此时nginx 肯定会 reset connect 。 我都关闭连接了 还发我干嘛~~

client - nginx
nginx 返回客户端504 并发送 FIN 关闭连接

总结流程
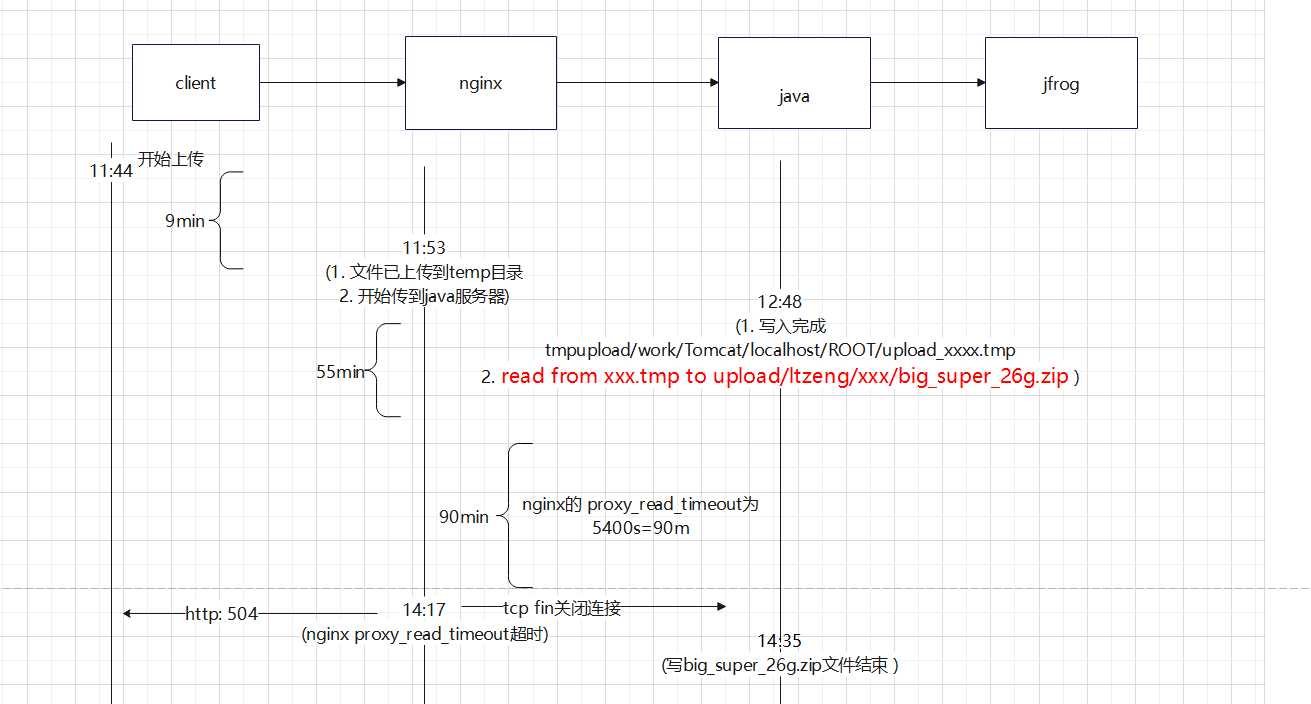
结论
为什么用户之前没有504 ?
因为之前的云硬盘读写性能相对更好, read + write < 5400s 。
问题解决
炎融云性能问题
存储团队开启cache配置后, 性能基本和云硬盘差不多了 client_cache_type = cache
代码不合理的地方, 文件上传到临时目录再转到目标目录, 从copy改为类似mv的操作