
案例分析-java-cpu高在测试环境完美重现的过程
现象
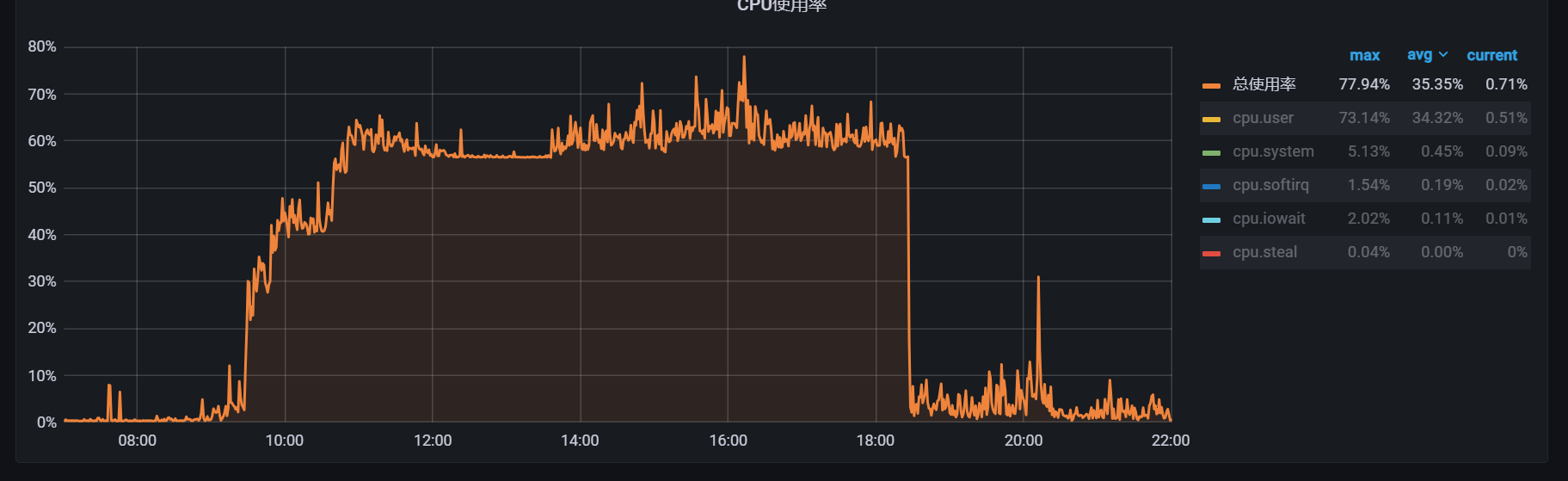
线上服务ideploy(内部CICD的cd) cpu使用率突发升高基本保持在 85%+
- 机器A
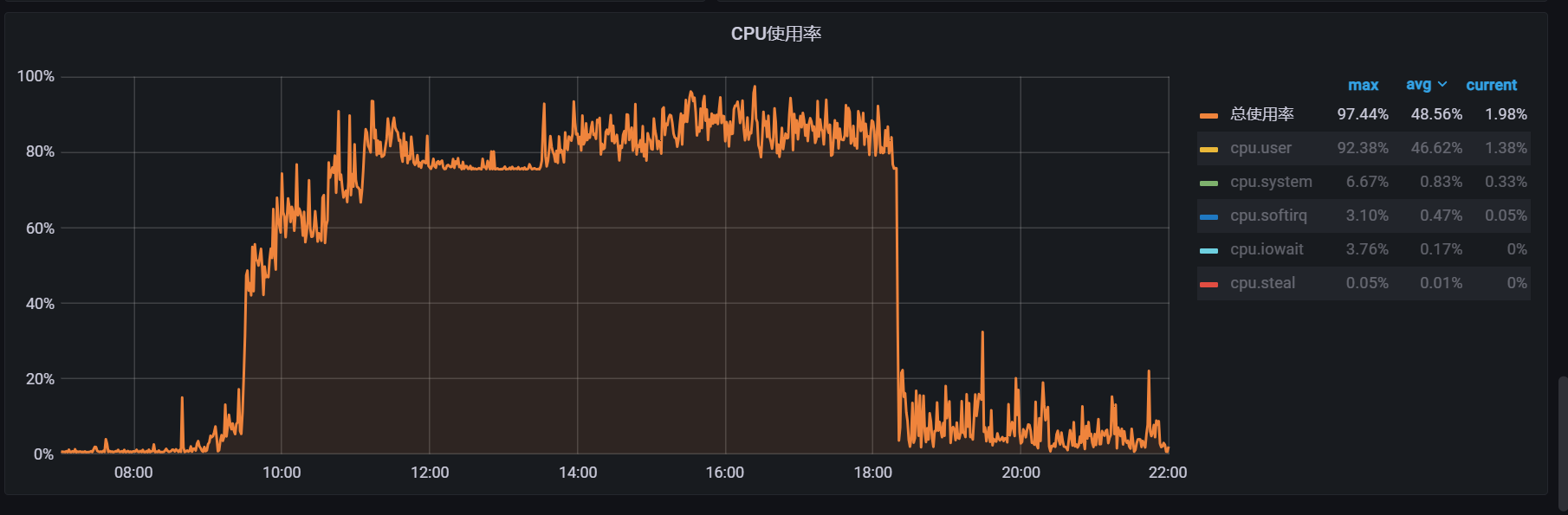
- 机器B
分析
告警是下午4点多发出的 , 收到告警后, 看监控很明显从 9:30 开始cpu就开始上升了, 公司一般8:30上班, 9点多流量会
对比一下平常的cpu曲线
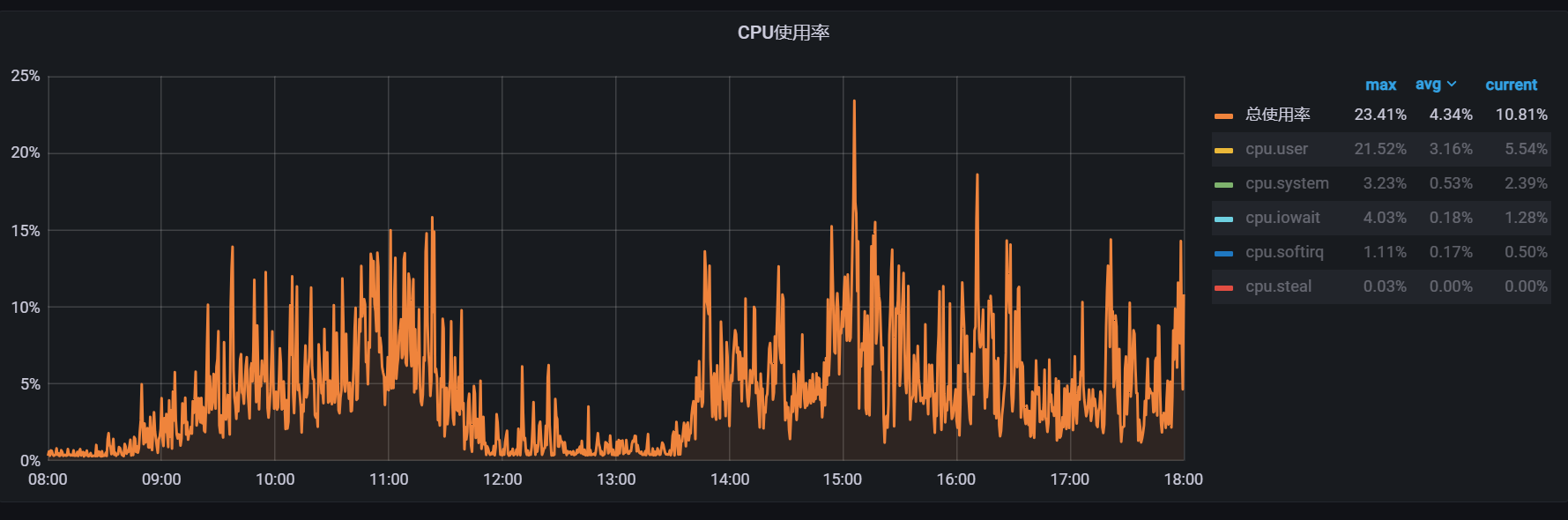
怀疑1 今天有大量流量?
通过elk拉取日志看
看了几天的数据发现 nginx请求两9:00-10:00之间在150W左右, 今天日志请求两也在156W 。看起来入口流量正常
怀疑2 可能是特殊的用户操作出发
找到问题点
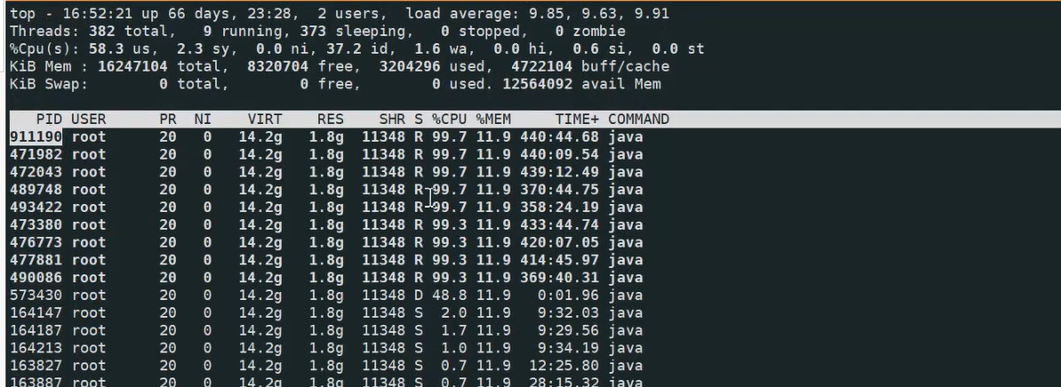
那就具体看这个进程到底在做啥?
top -Hp 163779
观察一会发现占用cpu高的线程就那几个 , 那就很明确了肯定是那几个线程导致的
进入容器导出 jstack 注意如果 jstack在容器里执行, top -Hp 也需要进入容器执行
jstack -l 1 > jstack.out进入容器执行 top -Hp 1
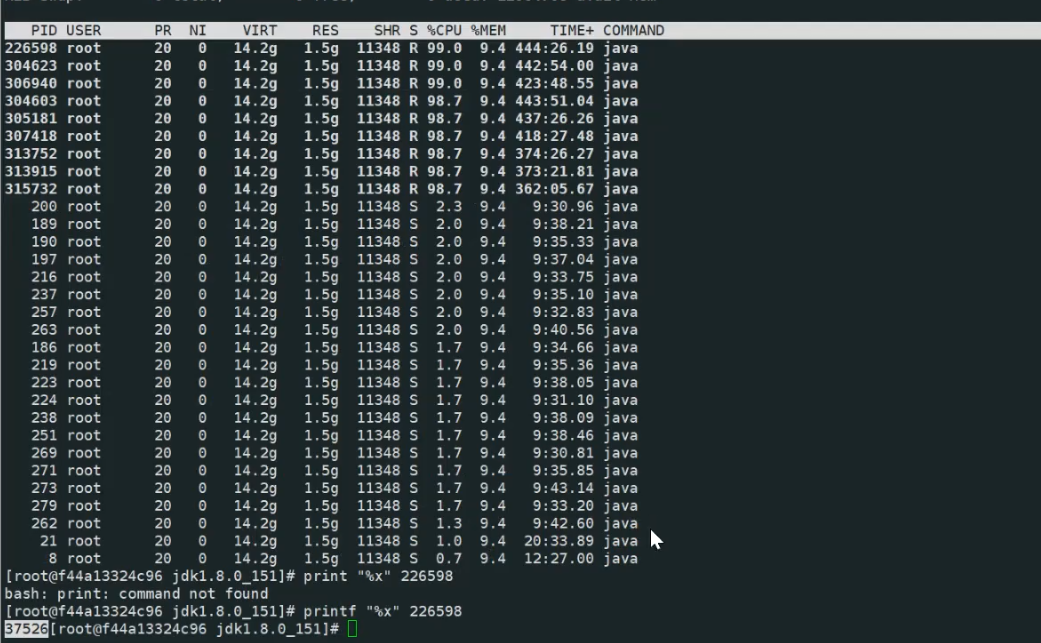
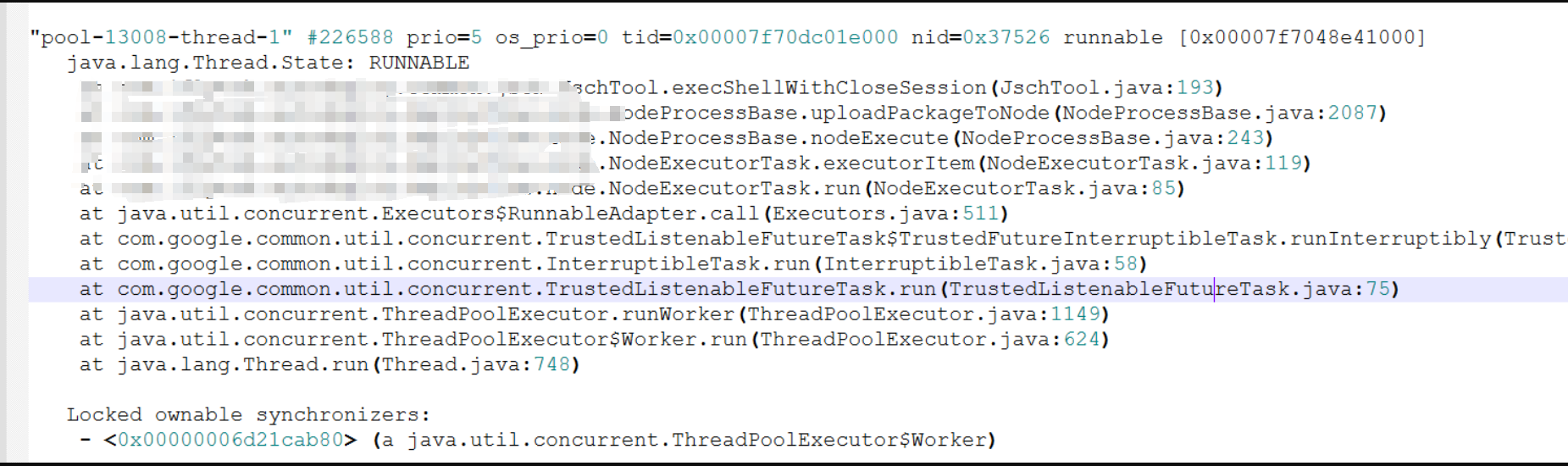
然后把所有cpu占用高的线程都找了下, 都是出现在这个堆栈
源码分析
问题出现在连接一台机器执行命令
怀疑是下面的 while(true)
channel = session.openChannel(“exec”);
InputStream in = channel.getInputSteam()
channel是没有关闭的, in.avaiable() == 0 的情况 就能触发死循环。
此时研发想起来早上处理过一个用户的问题, 用户部署任务卡死的问题, 可能跟这个问题相关,
确认下日志发现确实时间上吻合。
找用户排查
找到用户连的机器发现,机器进不去了, ssh xxx 进去后就没有返回了。 这个和上面的分析很吻合, 可以建立链接,但是后面就没有返回了。 用户直接重启了机器后, 发现cpu还是没有下降。
蓝绿部署将服务重启
通过蓝绿切流量将2台机器的服务重启,释放卡死的线程。 cpu 恢复正常
问题重现
虽然cpu恢复了,但是为了找到怎么触发的 还得需要在测试环境进行问题重现
模拟 网络延迟 120s
通过blade 模拟 ideploy <-> 运行命令的机器 网络delay > 120 s
命令:
# 部署机器里执行
./blade create network delay --interface eth0 --timeout 1200 --time 100000 --destination-ip ideploy-服务ip现象: 不能模拟cpu上升的情况, 但是打日志发现是此时程序执行的命令是 df /deveops/xxx/xxx/xx 目录 来确认机器是否有足够的空间来部署
模拟 df /deveops 卡住的情况
尝试 blade 模拟磁盘读读高负载的情况- 未复现
模拟磁盘读性能下降 - 未复现
此时求助 存储大佬。 大佬提供了一个好的命令可以限制硬盘的读写性能
- blkio.throttle.read_bps_device:磁盘读取带宽限制
- blkio.throttle.read_iops_device:磁盘读取IOPS限制
命令
# 查看对应磁盘编号,如253:16 ll /dev/block/ | grep vdb # 限制读1 B/s echo "253:16 1" >> /sys/fs/cgroup/blkio/blkio.throttle.read_bps_device现象: 限制了只有1b/s的读 还是没有重现cpu上升的情况, 但是这个命令超级好用, 还有个线上问题通过这个命令能够重现,后面有机会再分享
将/deveops 挂载nfs网络盘 - 成功复现
nfs一般产线环境都不建议用, 一旦服务端出现问题, nfs客户端直接卡死
我们将 /deveops 挂载nfs 网络盘, 然后再利用blade 模拟 部署机器<->nfs-server 的网络延迟180s
- 重现命令:
mount -t nfs xxxxx:/data/test1 /deveops
./blade create network delay --interface eth0 --time 180000 --timeout 12000 --destination-ip xxxxxx现象: 成功重现 cpu 上升的情况
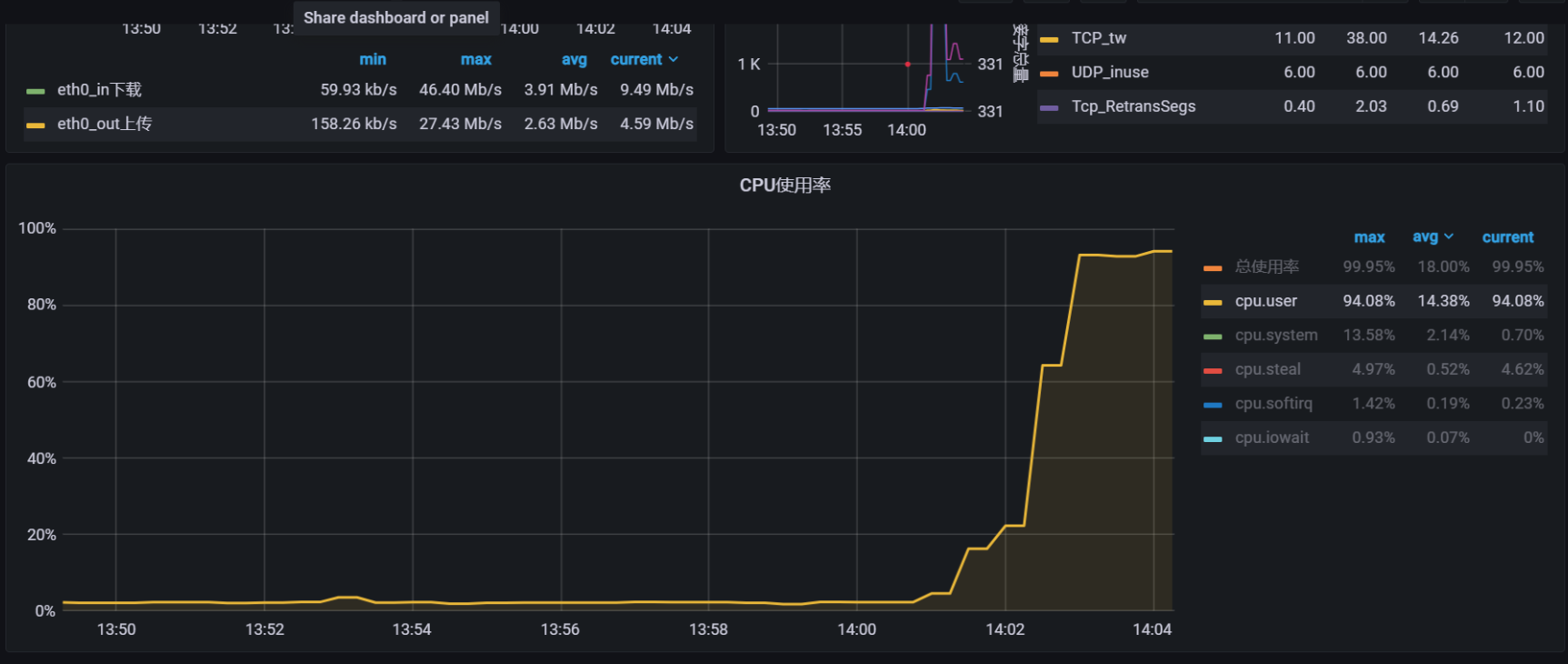
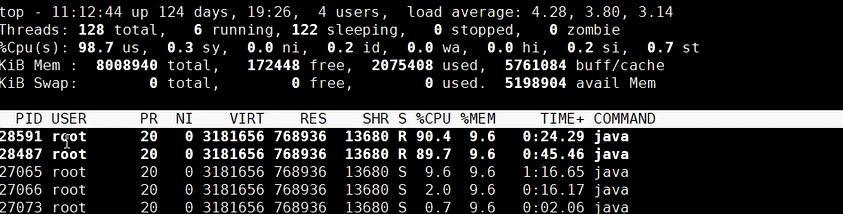
通过jstack 分析确实这两个线程都是卡在相同的位置
总结
- java cpu高思路 分析top -Hp xxx -> jstack -l pid -> 找源码
- 可以通过 nfs 盘来模拟 df /xxxx 卡住的情况